关于深度学习的人体动作识别算法调研
关于深度学习的人体动作识别算法调研
本次的新生研讨课上,老师给我们详细的介绍了AI(深度学习)在生活场景中的应用与原理,而我对其中的AI图像识别(计算机视觉)饶有兴趣,又了解到去年我们学校在全国大学生软件创新大赛上的获奖作品“袋鼠教练”,其采用了深度学习的人体动作识别算法,于是展开进一步调研。
1. 概述
什么是人体姿态识别?就是通过图像或视频,对人体关键点进行检测的过程。
2.人体动作识别技术的应用前景?
1.步态识别安防
2.体感游戏
3.异常行为检测
4.体育训练及分析
5.人机交互
6.短视频特效
3. AI识别人的五重境界:
1.有没有人
2.人在哪里
3.这个人是谁
4.这个人此刻处于什么状态
5.这个人在当前一段时间里做什么
从识别角度来说,我们可以分成两个大方向,一是人体身体关键特征点识别,这里特征点分为2d特征点和3d特征点,部分方案只支持2d特征点;二是人体动作识别,比如用户在做什么动作,举一个很简单的例子,我们可以通过mediapipe识别出用户在做俯卧撑或者深蹲等。
4.实现的难点
确定人体四肢、复杂的自遮挡、自相似部分以及由于服装、体型、照明、以及许多其他因素。
由于人体具有相当的柔性,会出现各种姿态和形状,人体任何一个部位的微小变化都会产生一种新的姿态,同时其关键点的可见性受穿着、姿态、视角等影响非常大,而且还面临着遮挡、光照、雾等环境的影响,除此之外,2D人体关键点和3D人体关键点在视觉上会有明显的差异,身体不同部位都会有视觉上缩短的效果
5. 具体算法实现(引自CSDN博客)
自上而下(Top-down)算法:
首先检测人体,使用前置的目标检测网络标识出画面中的人体的边界框,HRnet()通过多分辨率融合以及保持高分辨率的方法极大的 提高了关键点的预测精度。由于Top-down在目标检测阶段就消除了大部分的背景,因此很少有背景噪点或其他人体的关键点,简化了关键点热图估计,但是在人体目标检测阶段会消耗大量的计算成本,并且不是端到端的算法
eg:Blazepose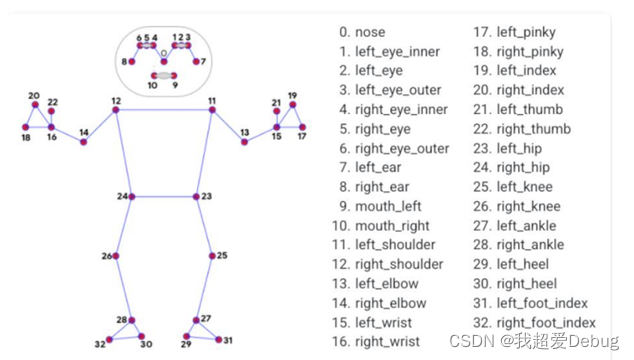
传统的coco数据集竞赛要求的是18个关键点,而blazepose可以达到33个关键点
eg:Mediapipe
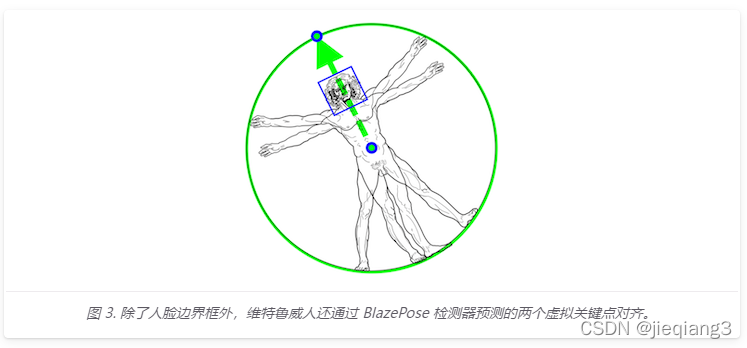
Mediapipe检测是基于BlazeFace模型,明确地预测了两个额外的虚拟关键点,这些虚拟关键点将人体中心、旋转和缩放牢固地描述为一个圆圈。受莱昂纳多的维特鲁威人的启发,我们预测了一个人臀部的中点,外接整个人的圆的半径,以及连接肩部和臀部中点的线的倾斜角。