关于大数据推荐算法的调研
关于大数据推荐算法的调研
本次的新生研讨课上,老师向我们介绍了利用AI进行信息检索的技术,而其中有一点是关于当下热点,各大视频购物平台大数据的智能推荐,于是我怀着好奇对其进行调研。
1.推荐算法的概述(引自百度百科)
推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西,应用推荐算法比较好的地方主要是网络。所谓推荐算法就是利用用户的一些行为,通过一些数学算法,推测出用户可能喜欢的东西
起源:美国某大学研究小组想要制作一个名为Movielens的电影推荐系统,从而实现对用户进行电影的个性化推荐。
2.各种推荐算法分类
| 推荐方法 | 优点 | 缺点 |
|---|---|---|
| 基于内容推荐 | 推荐结果直观,容易解释;不需要领域知识 | 新用户问题;复杂属性不好处理;要有足够数据构造分类器 |
| 协同过滤推荐 | 新异兴趣发现、不需要领域知识;随着时间推移性能提高;推荐个性化、自动化程度高;能处理复杂的非结构化对象 | 稀疏问题;可扩展性问题;新用户问题;质量取决于历史数据集;系统开始时推荐质量差; |
| 基于关联规则推荐 | 能发现新兴趣点;不要领域知识 | 规则抽取难、耗时;产品名同义性问题;个性化程度低; |
| 基于效用推荐 | 无冷开始和稀疏问题;对用户偏好变化敏感;能考虑非产品特性 | 用户必须输入效用函数;推荐是静态的,灵活性差;属性重叠问题; |
| 基于知识推荐 | 能把用户需求映射到产品上;能考虑非产品属性 | 知识难获得;推荐是静态的 |
3.对于关联规则推荐算法原理的理解
关联规则就是在一个交易数据库中统计购买了商品集X的交易中有多大比例的交易同时购买了商品集Y,其直观的意义就是用户在购买某些商品的时候有多大倾向去购买另外一些商品。比如购买牛奶的同时很多人会购买面包。
eg: 如何给买啤酒的人推荐其他的食品?
从全量的订单交易信息中找到买啤酒的人还都买了其他什么东西
在这些东西中,找出被买次数的 topn
将 topn较大的个体推给其他买啤酒的人
4.针对关联规则推荐算法原理的深入调研(部分引自知乎)
协同过滤(Collaborative filtering, CF)是最常用的推荐算法之一。即使数据科学的新手也可以用它来构建自己的个人电影推荐系统。
我们想给用户推荐东西,最合乎逻辑方法是找到具有相似兴趣的人,分析他们的行为,并向用户推荐相同的项目。另一种方法是看看用于以前买的商品,然后给他们推荐相似的。
这就构成了两种基本方法:基于用户的协同过滤和基于项目的协同过滤。
无论哪种方法,推荐引擎有两个步骤:
了解数据库中有多少用户/项目与给定的用户/项目相似。
考虑到与它类似的用户/项目的总权重,评估其他用户/项目,来预测你会给该产品用户的打分。
为了量化这种相似度,数据科学家引入了偏好矩阵,行向量:类型;列向量:用户评分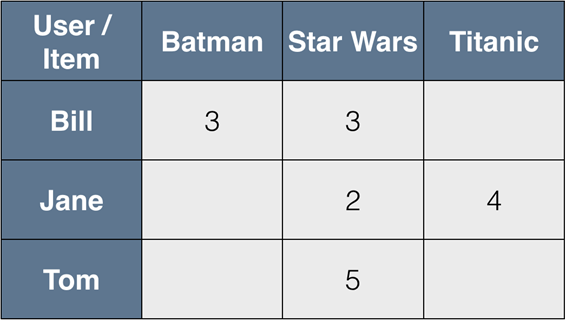
通过已知元素结合一些运算,填充未知位置就得到了哪个类型对于Tom得分最高进行推荐。

